Від букв до цифр - Аналіз чату в Телеграмі
Перетворіть повсякденні переписки у захопливі візуалізації даних. Дізнайтеся, як експортувати, аналізувати та візуалізувати історію чатів у Телеграмі, щоб розкрити приховані патерни вашого спілкування.
На сьогодні Телеграм є одним із найпопулярніших месенджерів, який швидко розвивається завдяки зручності, безпеці та широкому функціоналу. З кожним днем додаток продовжує збільшувати свої можливості, а також покращувати існуючі функції, щоб залучати користувачів.
Програма пропонує унікальну для месенджерів функцію — повноцінний експорт історії чатів із збереженням усієї структури даних. Користувачі можуть вивантажувати історію повідомлень, медіафайли та навіть метадані чатів у зручному форматі. На відміну від інших месенджерів, це дозволяє:
- Зберігати резервні копії без обмежень платформи
- Аналізувати статистику (частота спілкування, активність)
- Переносити дані між пристроями без втрат
Отримавши доступ до структурованого експорту переписок, ми можемо не просто переглядати історію спілкування, а й виявляти цікаві закономірності, які зазвичай приховані за потоком повідомлень.
Експорт
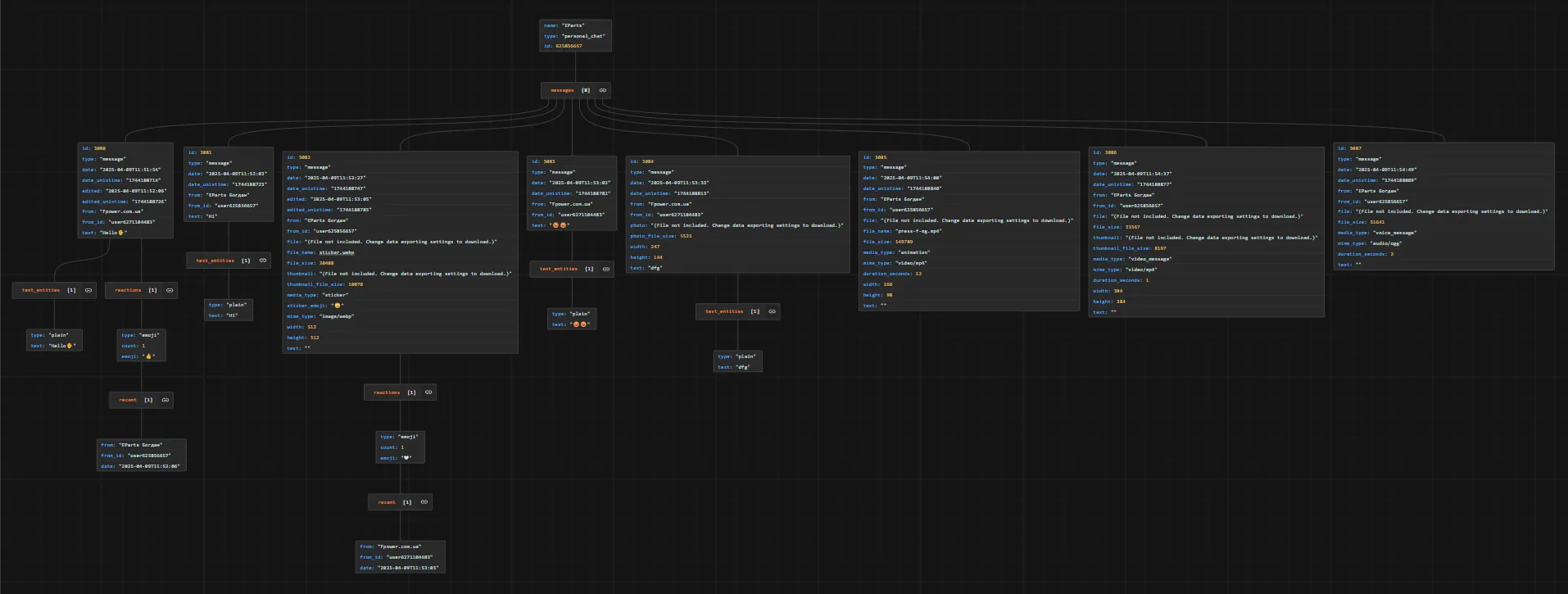
Експортувати дані можна як для окремого чату так і для всіх груп одночасно. Для цього, відкривши розмову, вибираємо три крапки, експортуємо історію чату, і вибираємо формат JSON, як показано на малюнку
!!! Експортування історії чатів доступна тільки у десктопній версії телеграму.
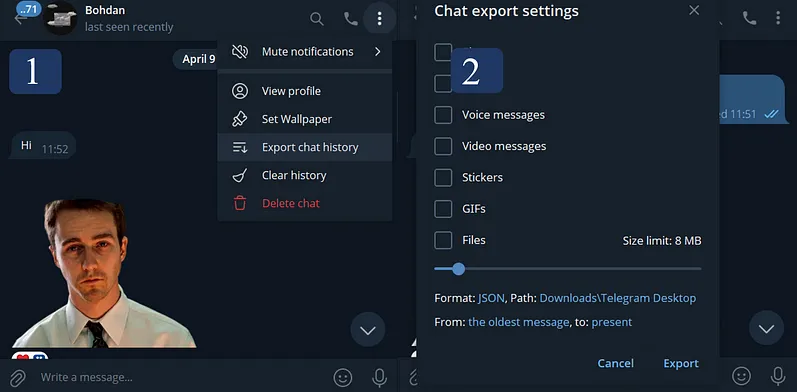
Так, ми отримуємо файл result.json який має наступну структуру:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"name": "Bohdan",
"type": "personal_chat",
"id": 123456789,
"messages": [
{
"id": 3080,
"type": "message",
"date": "2025-04-09T11:51:54",
"date_unixtime": "1744188714",
"edited": "2025-04-09T12:34:20",
"edited_unixtime": "1744191260",
"from": "Fpower.com.ua",
"from_id": "user6271104483",
"text": "Hello ✋",
"text_entities": [
{
"type": "plain",
"text": "Hello ✋"
}
.....
]
}
]
}
Обробка даних
Для кращого розуміння, можна переглянути цей файл у табличному вигляді, користуючись наступним сервісом JsonGrid1
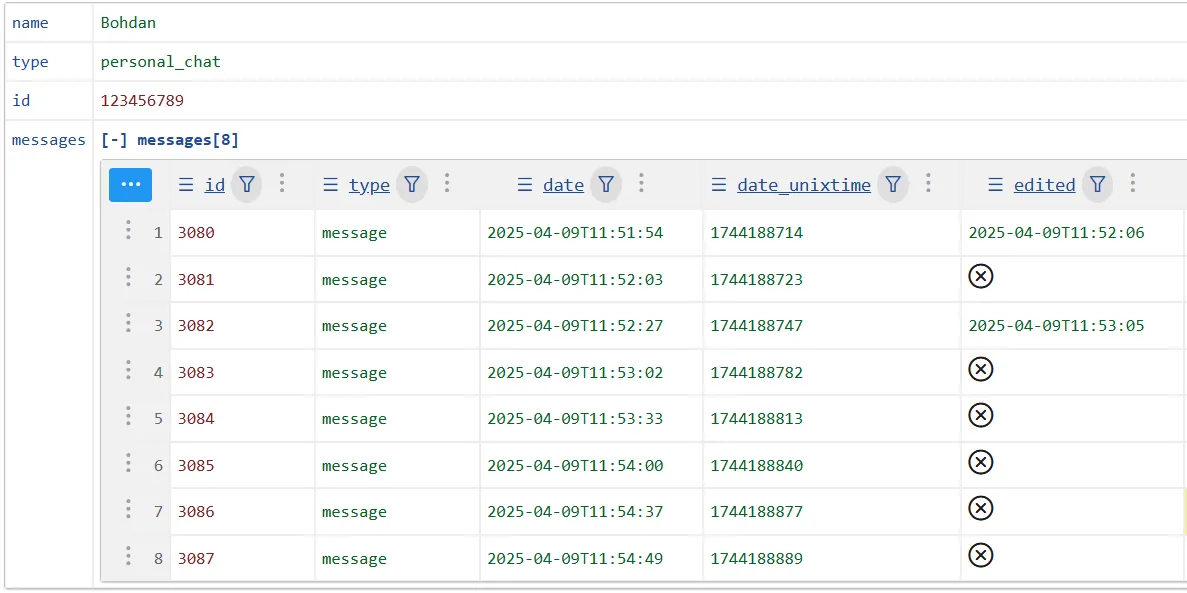
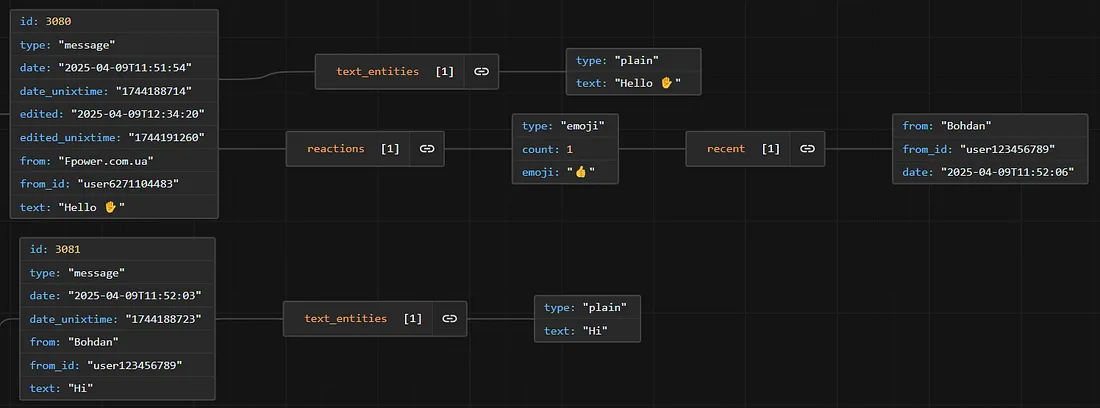
Основні поля можна поглянути на фото нижче, так як вони відрізняються, залежно від типу повідомлення (може бути текст, фото, GIF…)2
 Тепер, спробуємо перетворити цей JSON у зручний для нас табличний вигляд
Тепер, спробуємо перетворити цей JSON у зручний для нас табличний вигляд
1
2
3
4
5
6
7
8
9
import json
import pandas as pd
with open('result.json', 'r', encoding='utf-8') as f:
data = json.load(f)
messages = data['messages']
df = pd.json_normalize(messages)
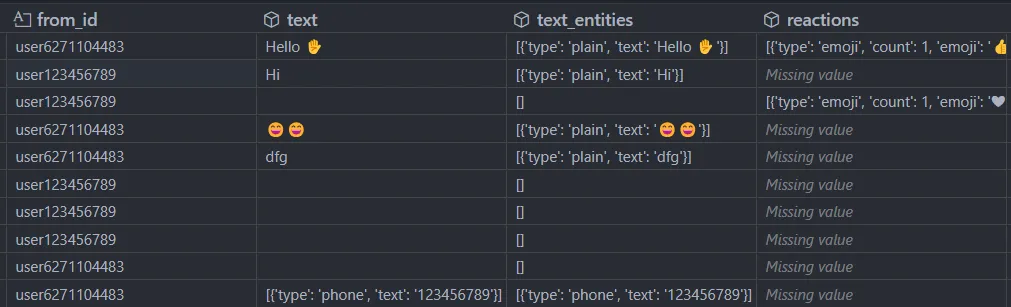
Поле reactions містить у собі реакцію користувача на повідомлення, розділимо цей стовпець на два окремі: кількість реакцій на повідомленні та самий смайлик
1
2
3
4
5
6
7
8
9
10
11
df['reaction_count'] = df['reactions'].apply(
lambda x: x[0]['count']
if isinstance(x, list) and len(x) > 0 and 'count' in x[0]
else None
)
df['reaction_emoji'] = df['reactions'].apply(
lambda x: x[0]['emoji']
if isinstance(x, list) and len(x) > 0 and 'count' in x[0]
else None
)
Отримаємо потрібні нам стовпці

Візуалізація
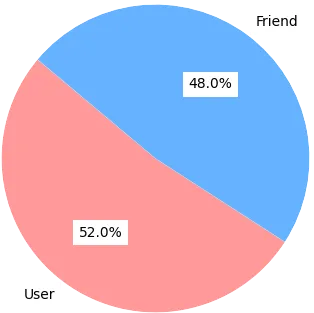
Тепер, ми можемо проаналізувати наше спілкування. Розрахуємо кількість повідомлень від кожного користувача, так ми дізнаємось, хто балакучіший
1
2
3
4
5
6
7
8
9
10
11
12
import matplotlib.pyplot as plt
message_counts = df['from'].value_counts().reset_index()
labels = message_counts['from']
sizes = message_counts['count']
plt.figure(figsize=(5, 5))
plt.pie(sizes, labels=labels, autopct='%1.1f%%', startangle=140, colors=['#ff9999', '#66b3ff'])
plt.title("Senders' posting", fontsize=16, fontweight='bold')
plt.show()
Додаток Flourish3 дозволяє створювати інтерактивні діаграми та графіки різних видів, тому ми скористуємося ним для візуалізації.
Згрупуємо дані за реакціями на повідомленнях у користувачів та імпортуємо файл до Flourish
1
2
grouped = emoji_df.groupby(['from', 'reaction_emoji'])['reaction_count'].sum().reset_index()
grouped.to_csv('reaction_emoji_grouped.csv', index=False, encoding='utf-8-sig')

З діаграми видно, що одна людина є в чотири рази більш схильною на поставити реакцію на повідомлення.
Згрупуємо дані за типом надісланого медіаповідомлення
1
2
3
4
media_type = df[~df['media_type'].isnull()].copy()
media_type = media_type[['from', 'media_type', 'date']]
media_type_grouped = media_type.groupby(['from', 'media_type'])['date'].sum().reset_index()
media_type_grouped.to_csv('media_type_grouped.csv', index=False, encoding='utf-8-sig')
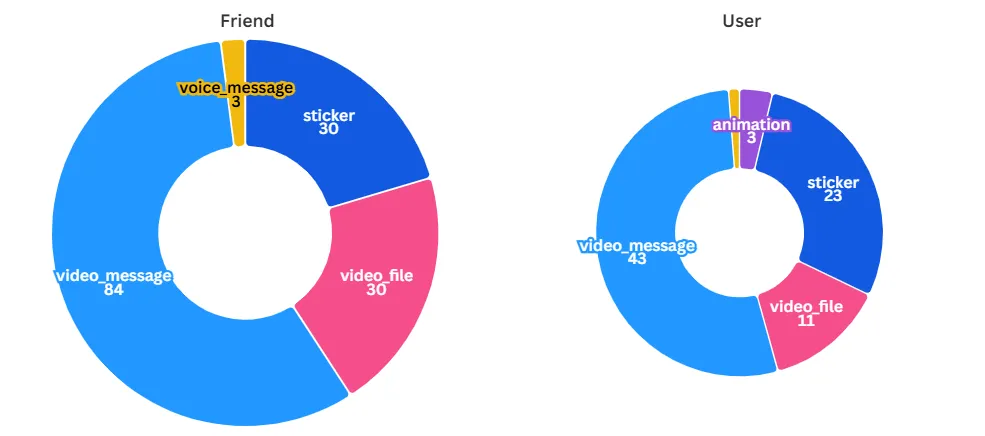
Отже, наш друг набагато частіше надсилає відеоповідомлення, хоча й загальна кількість повідомлень у користувача більша. Чи не забавно?
1
2
3
4
df.loc[:, 'year_month'] = df['date'].str[:7]
date_grouped = df.groupby(['from', 'year_month'])['date'].count().reset_index()
date_grouped = date_grouped.pivot(index='year_month', columns='from', values='date').reset_index()
date_grouped.to_csv('date_grouped_by_month.csv', index=False, encoding='utf-8-sig')
Поглянемо на кількість надісланих повідомлень кожного місяця протягом останніх років
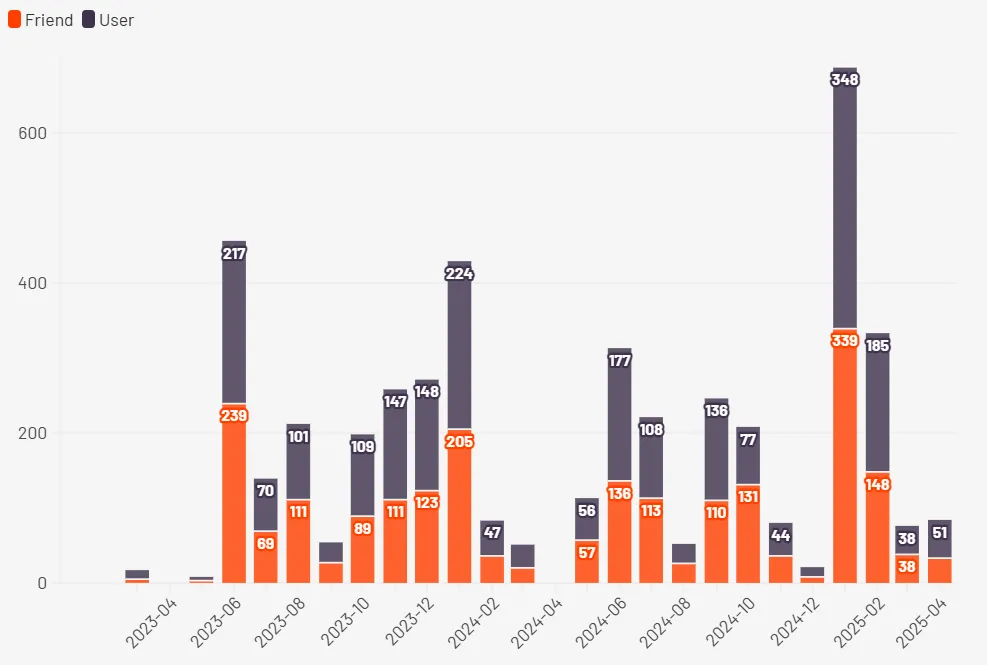
Видно, що раніше спілкування було частішим, але в кінці почалась миттєва активність.
Кількість це звісно добре, а як же якість? Різні користувачі по-різному надсилають повідомлення, хтось всю суть вкладає в одне, а хтось надсилає кожне речення окремо. Поглянемо на середню довжину повідомлення, а також найдовше для кожного
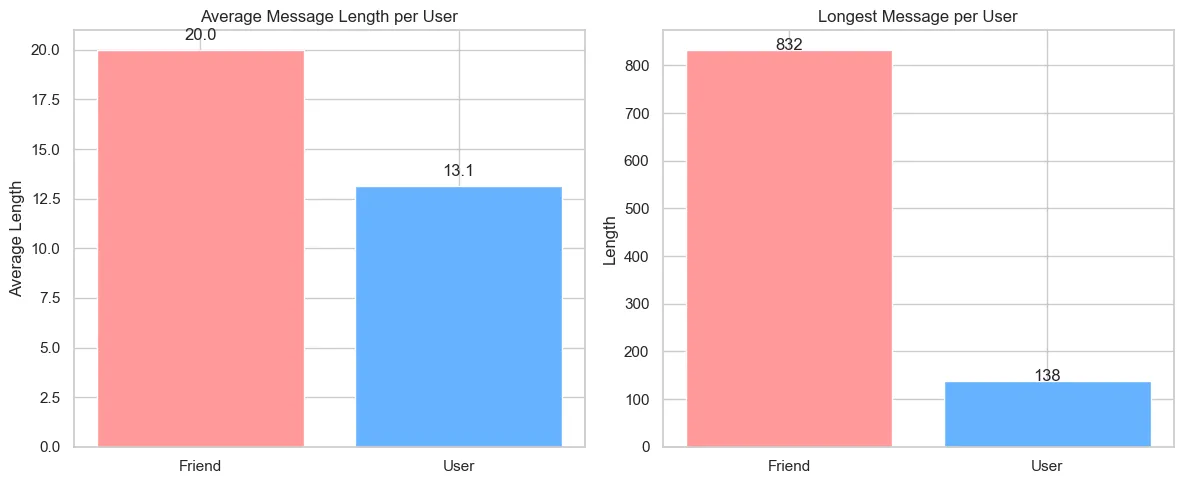
Хоч і користувач надсилає більше повідомлень, але вони є меншими за кількістю символів. Отже, складається уявлення, що користувач любить писати речення, а то й слова новим повідомленням, а його співрозмовник вкладає весь зміст в одне.
Цікаво також буде глянути, в які години та дні спілкування відбувалося частіше. В цьому нам допоможе теплова діаграма
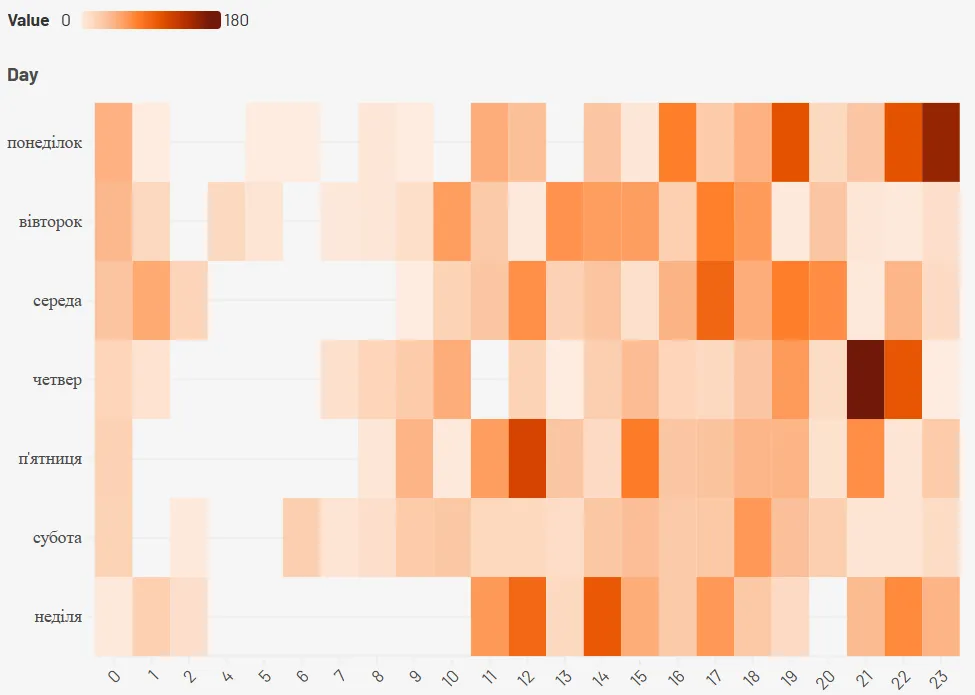
Отже, найчастіше повідомлення надсилалися в четвер о 20:00 годині та в понеділок об 23:00. В період від першої до дев’ятої ранку, що очевидно, повідомлення майже не писалися
Ну і наостанок, глянемо на слова, які використовуються найчастіше

Висновок
Аналіз чату в Телеграмі — це наче розмова з самим собою в дзеркалі даних. Ми бачимо не просто набір слів, а візерунки спілкування: хто пише частіше, але коротше, хто рідше, але детальніше; коли спалахує найбільше емоцій і навіть у який час виникають найцікавіші обговорення. Ці дані — не суха статистика, а відбиток справжньої взаємодії, де кожен символ, реакція чи відправлений файл розповідають про те, як ми спілкуємося насправді.
Тому експорт переписки — це не просто архів, а можливість побачити діалог із сторони, де кожне повідомлення стає частиною більшої картини. І якщо придивитися, ці дані розповідають історію не лише про те, що було сказано, але й про те, як — і, можливо, навіть чому.
P.S. Посилання на GitHub з повним кодом : https://github.com/AdobyY/Telegram-chat-analyzer/blob/main/EDA.ipynb